-
Permalink
On twitter.com
 ❤️ 25 Favorites
Mood 0
❤️ 25 Favorites
Mood 0
-
I think it is genuinely, non-sarcastically, worthwhile to engage in examining Google's efforts here, because it is important to understand what is occurring and why it is occurring the way it is. So let's understand the threat model and engage with it.Permalink On twitter.com
♻️ 4 Retweets
❤️ 16 Favorites
Mood +2 🙂
-
For you non-engineers, let's translate this down: "threat model" in this case is (basically) a complicated way of saying "What's the problem?" So, what, according to Google, is the problem?Permalink On twitter.com
❤️ 6 Favorites
Mood -6 🙁
-
Graf 3 makes this very clear. The problem, according to Google, is that users want privacy but "publishers' economic viability" (how they make money) is dependent on tracking users in a way that is similar to assigning them a web-wide global identity.Permalink On twitter.com
 ♻️ 1 Retweets
❤️ 8 Favorites
Mood 0
♻️ 1 Retweets
❤️ 8 Favorites
Mood 0
-
I think this is an incorrect statement. This is based on a dependence on a particular way of doing things. Sure, publishers currently use personally identifiable information for ad targeting, but that's because that is the state of the ecosystem...Permalink On twitter.com
♻️ 3 Retweets
❤️ 27 Favorites
Mood 0
-
Let's not get into the motives for stating the problem this way (but worth noting: Google makes a lot of money off of tagging and tracking PII, so they are clearly as--if not more--threatened than any publisher), but also, we could imagine a different way. digiday.com/media/were-building-for-media-businesses-of-tomorrow-how-the-washington-post-is-preparing-for-a-cookieless-future/Permalink On twitter.com
♻️ 2 Retweets
❤️ 16 Favorites
Mood +1 🙂
-
So I think the core threat: 'increased privacy makes it unlikely that publishers can continue to survive' is very much worth challenging. If browsers turned off *all* the user tracking and fingerprinting tomorrow would marketing budgets suddenly disappear? I don't really think soPermalink On twitter.com
♻️ 11 Retweets
❤️ 26 Favorites
Mood -2 🙁
-
In a world where tracking was banned and user privacy was fully enforced, I suspect there would be some period where the ecosystem adapted that wouldn't be great for many publishers, but it would eventually bounce back. The brands are still looking to advertise after all.Permalink On twitter.com
♻️ 1 Retweets
❤️ 9 Favorites
Mood 0
-
So I don't really agree that the only way forward for effective advertising for publishers is full-on user tracking, which seems to be the initial threat at top here. But let's continue to parse the document...Permalink On twitter.com
❤️ 5 Favorites
Mood +3 🙂
-
100% agree with graf 5Permalink On twitter.com
 ❤️ 3 Favorites
Mood +1 🙂
❤️ 3 Favorites
Mood +1 🙂
-
So do we need *any* identity model? Google's post here doesn't engage with that question, but it *is* worth engaging, especially for any non-technical people. The answer is: yes. You want to sign in to sites, you want to pay for things, etc... all that needs some sort of identityPermalink On twitter.com
❤️ 5 Favorites
Mood +3 🙂
-
At one extreme is our current world, where every login can potentially plant more PII to allow you to be targeted. Obviously, people--users of browsers and publisher sites--are increasingly uncomfortable with this current approach.Permalink On twitter.com
❤️ 1 Favorite
Mood -1 🙁
-
At the other end is something like the Privacy Pass proposal, which allows users to maintain an identity in one place and use it to log in to things without ever having to pass PII to any entity but the single trusted site/provider. privacypass.github.io/Permalink On twitter.com
♻️ 1 Retweets
❤️ 10 Favorites
Mood +4 🙂
-
Google takes it as a given here that: 1: You will need a single identity across some range of web activity (so what is that range?) 2: That some data will have to move from an identity held by one entity to an identity held by another identity.Permalink On twitter.com
 ♻️ 1 Retweets
❤️ 5 Favorites
Mood 0
♻️ 1 Retweets
❤️ 5 Favorites
Mood 0
-
More simply: 1: You need an identity on the web in some situations sometimes beyond a simple login to a site. 2: Your identity = information about you & some of that information about you should be able to move from your identity on one site to your identity on another site.Permalink On twitter.com
❤️ 6 Favorites
Mood 0
-
Alright. I agree, for the web, browsers, everyone to move forward these are indeed questions that need answering. You still want to log in to things. Also, if you've ever used Apple, Google, PayPal or FB to log into things, then information needs--to some degree--to be shared.Permalink On twitter.com
❤️ 5 Favorites
Mood +3 🙂
-
Ok. Now things get /complicated/. The threat is modeled, an answer proposed. 1st: First Party Sites get a distinct identity of users. A first party site (eTLD+1) is the site you are on. If you are reading this on Twitter dot com, Twitter dot com is your 1st Party.Permalink On twitter.com
❤️ 6 Favorites
Mood -2 🙁
-
Ok. So I do have a challenge to pt 1 of proposal 1. Which is: should mysite dot com get to assign you an identity without your consent? This is generally accepted in this document and is a baseline assumption of the internet right now, but doesn't need to be...Permalink On twitter.com
♻️ 2 Retweets
❤️ 7 Favorites
Mood +2 🙂
-
Notably sites who follow GDPR & EU cookie rules can potentially end up not assigning you a cookie at all! (cookie = some data to begin 1st party tracking in your browser). I don't think we have to take it as a given that a site gets to assign you an identity at all! So mark that.Permalink On twitter.com
♻️ 2 Retweets
❤️ 7 Favorites
Mood 0
-
Part 1, point 2: "The central privacy threat is joining these per-site identities across distinct first parties. Browsers impose limits (on cookies, fingerprinting, and other state) with the goal of preventing the joinability of these per-1p identities." Agreed 100%!Permalink On twitter.com
❤️ 4 Favorites
Mood -4 🙁
-
Ok, point 3 is sorta complicated for its relatively short length. But at a basic level, the proposal is: Currently, browsers will only define one domain as First Party. But Google proposes that more than one domain be allowed to be considered 1st party - mikewest.github.io/first-party-sets/Permalink On twitter.com
❤️ 1 Favorite
Mood 0
-
Once again, assuming a less technical audience here needs this broken down so hopefully I can get it right:Permalink On twitter.com
❤️ 1 Favorite
Mood +1 🙂
-
Currently if you arrive on twitter dot com to read this, twitter can place a cookie on you. In that situation that cookie is accessible only to twitter dot com and subdomains (hi.twitter dot com for example). But not to myblog dot com.Permalink On twitter.com
♻️ 1 Retweets
❤️ 3 Favorites
Mood +1 🙂
-
I haven't dug deep in the history or anything but generally this is considered a good idea for preserving the security of your identity but also because some web developers are idiots and might store your password in plaintext on the cookie. Makes sense!Permalink On twitter.com
❤️ 2 Favorites
Mood +3 🙂
-
Now... for some reason big tech companies have created a situation wherein this is a problem. See Google controls youtube dot com and google dot com. Apple has apple dot com and icloud dot com. These single companies have multiple 1st party domains need to talk to each other.Permalink On twitter.com
❤️ 1 Favorite
Mood -1 🙁
-
Can I be honest with you? I might be an idiot here, but I have no idea why these companies do this. Why not icloud dot apple dot com or youtube dot google dot com? If you know please tell me because I'd like to!Permalink On twitter.com
❤️ 9 Favorites
Mood +1 🙂
-
There might have been a time when doing that restricted infrastructure (kept many sites on one physical server) but that has long not been the case. So like... I understand why big tech companies w/all these domains have this problem, but I'm not sure why it's the users' problemPermalink On twitter.com
❤️ 4 Favorites
Mood -3 🙁
-
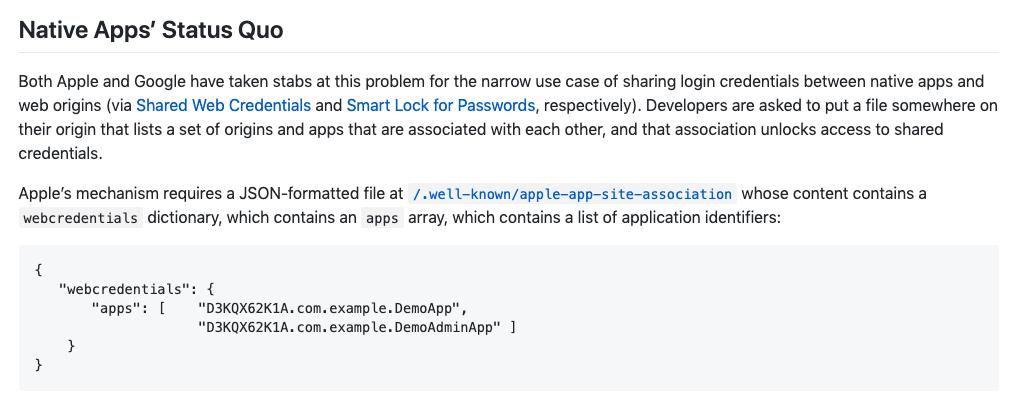
There's an *additional* problem which is that Native Web Apps have their own domains and like... if you have an account on myblog dot com you want to be able to allow it to sign you in to MyBlogApp also... so there's that. Apple and Google have existing methods for handling this.Permalink On twitter.com
 ❤️ 1 Favorite
Mood +2 🙂
❤️ 1 Favorite
Mood +2 🙂
-
But for... arbitrary reasons? it appears that Apple and Google have different ways of telling apps and sites they have permission to interact with each other. Fundamentally though they are sets of ids of apps and ids of websites that are allowed to talk to each other.Permalink On twitter.com
❤️ 3 Favorites
Mood 0
-
Ok, so we do *need* this. Apps, despite pretending like they are some magical other world, are basically just web pages in boxes that need to talk to other web pages easily otherwise the user experience goes to crap.Permalink On twitter.com
♻️ 1 Retweets
❤️ 15 Favorites
Mood -2 🙁
-
Personally I think the solution to this is to get rid of all apps forever and just use web pages like our bearded internet hippie forefathers intended but I guess I am going to be in the minority there, so a unified standard would be helpful here!Permalink On twitter.com
♻️ 1 Retweets
❤️ 23 Favorites
Mood +6 🙂
-
But then we get into the meat of "First Party Sets" proposal and it is a little more uhhhh worrisome to me personally. Now the author is very clear here: "Though this isn’t a proposal that’s well thought out, and stamped solidly with the Google Seal of Approval" so slack givenPermalink On twitter.com
❤️ 2 Favorites
Mood +3 🙂
-
But also this proposal was listed as a significant point in thinking how the privacy of the web will be reworked and is t/f up for examination here.Permalink On twitter.com
❤️ 2 Favorites
Mood +1 🙂
-
Anyway, the issue I have is that the core is to allow browsers to consider a full set of *different* urls as 'first party urls'. So, MyBlog dot com could come to an agreement with AdServerX dot com and we could share our "first party status" across both sites.Permalink On twitter.com
❤️ 1 Favorite
Mood +3 🙂
-
Literally the first thing my mind skips to is gray hat web rings. Seems like this proposal at the point would open up a potential risk with little potential reward to users. After all, they can already do cross site sign in via other means. Chronotope/735605725351796737Permalink On twitter.com
♻️ 1 Retweets
❤️ 2 Favorites
Mood +1 🙂
-
The author of the piece also notes this could potentially be exploited by ad servers who will require entry into the first party set for use. I think they have a good explanation here of the risks, though not a full grasp on the scale and likelihood. mikewest.github.io/first-party-sets/#how-will-malicious-actors-abuse-this-mechanismPermalink On twitter.com
 ❤️ 3 Favorites
Mood -1 🙁
❤️ 3 Favorites
Mood -1 🙁
-
There's more detail in this proposal for shared first parties, but generally I think that the risk outweighs the reward. I'm not convinced by arguments otherwise here, but perhaps there is something I'm missing. We can set this aside for now and go back to the main proposal.Permalink On twitter.com
Mood -2 🙁
-
There's another piece of this point about limiting how identity is shared between these potentially first-party-shared domains, but it is very generally stated and unclear in implementation, so I'm just going to note the link github.com/jkarlin/flocPermalink On twitter.com
❤️ 1 Favorite
Mood 0
-
It's worth noting that this proposal does seem to imply that first-party-ness be shared between general providers (like an ad server, for example) and specific sites allowing for shared first party status between PayPal and my private tip jar site (to make up another example).Permalink On twitter.com
Mood +6 🙂
-
I'm not sure I agree w/a number of these points. I don't think browsers can sufficiently explain to non-technical users what is going on or why they should care. I'm not sure why this is *better* than current cross-site methods.Permalink On twitter.com
❤️ 2 Favorites
Mood +5 🙂
-
Generally I'm not sure this first party joining process would be good? Like... for one it requires manipulation of a number of chunks of your site and for two it would privilege preexisting entrants who use first-party-sharing over new entrants in a way that cross-site doesn'tPermalink On twitter.com
❤️ 3 Favorites
Mood +4 🙂
-
The proposal does make it clear that the number of first party shared domains would be limited which means that if I'm trying to use an ad server or network, or payment provider and it requires shared first-party-ness my capability to experiment w/new companies is curtailed.Permalink On twitter.com
Mood +3 🙂
-
Perhaps I'm not gaming this out properly? But this particular methodology seems to me to be a threat to the diversity of the web. I'd be interested in what other perspectives people have on this though.Permalink On twitter.com
❤️ 2 Favorites
Mood 0
-
There is another concern I have in that shared first-party-ness seems to authorize other domains to take action on your domain in a direct way that isn't as easy with cross site communication. That seems... worse? Like... significantly? I'm not sure what the advantage of that is.Permalink On twitter.com
Mood +3 🙂
-
Ok, onward to the question of 3rd parties.Permalink On twitter.com
Mood 0
-
(a good time to note: I'm not a browser engineer, so if I get stuff wrong, please correct me!)Permalink On twitter.com
Mood +2 🙂
-
Ok so the third party section bakes in some assumptions we will want to unpack before we even venture into details. First: that Third Parties (sites outside the site you are currently on) should and need to be allowed access to identity information from a 1st party...Permalink On twitter.com
❤️ 2 Favorites
Mood +1 🙂
-
This is a weird assumption because it runs counter to reality. There is a percentage of web users in the EU right now who, using the rights granted to them by GDPR explicitly disallow this and surf the web relatively fine.Permalink On twitter.com
♻️ 1 Retweets
❤️ 6 Favorites
Mood +1 🙂
-
Also it puts us in a web that excludes the idea of complying with, as I personally understand it, how GDPR works. As a starting point for a web spec recommendation 'only potentially illegal' seems like a bad start. But perhaps I'm missing something.Permalink On twitter.com
❤️ 5 Favorites
Mood -3 🙁
-
The second assumption is that it conflates its third point "composability" or that third party websites need to operate within first party websites with the of transmission of identity to third parties...Permalink On twitter.com
Mood 0
-
The proposal is correct that we can't assume that all websites should build or host their own ad server or analytics service. Also, embeds should work! But once again we have an example in the EU of how this can happen without transmitting identity information.On twitter.com
❤️ 2 Favorites
Mood 0
-
Simply put: you can absolutely run analytics and ad servers and embeds from third parties without having to grant those third parties identity information from the first party about the user. In fact, browser changes could make that *easier* to do.Permalink On twitter.com
♻️ 3 Retweets
❤️ 9 Favorites
Mood +1 🙂
-
With this in mind, I would prefer to challenge the first point in this section entirely. Should first parties have a way to delegate user identity to 3rd parties? That's the first question to be asked. Then we can move on to scale, means and browser role.Permalink On twitter.com
❤️ 1 Favorite
Mood -1 🙁
-
So. Point one is the question of if user identity should be delegated to third parties in a way that allows third parties to join them or not.Permalink On twitter.com
Mood +1 🙂
-
I think this is a dangerous path in general and somewhat unenforceable on a broad technical level. Once a third party receives data what it can do with it in the background is basically unlimited by browser or first party as far as I can see.Permalink On twitter.com
♻️ 1 Retweets
❤️ 4 Favorites
Mood -2 🙁
-
Which means the threat of joining per-site identities in the proposed system would essentially be unlimited and unchallenged, just--perhaps--technically more difficult. We're back at cross-site tracking in other words.Permalink On twitter.com
❤️ 2 Favorites
Mood -3 🙁
-
Perhaps browsers could limit the transmission of data to third parties (this is the next part of the proposal) but it will be a very careful balance.Permalink On twitter.com
Mood +2 🙂
-
Generally though, I think once we unhook the assumption that first parties need to give data to third parties that includes identity information about a user, it becomes clear this is an economic imperative not a technical one, which is fine, I accept people want to make money...Permalink On twitter.com
❤️ 3 Favorites
Mood +5 🙂
-
Let's state and accept one possibility here - which is third parties are forever blocked by browsers from receiving anything which could possibly be personal identity information and we're all instantly in compliance with GDPR and engage with the rest of the proposal.Permalink On twitter.com
❤️ 2 Favorites
Mood +1 🙂
-
I agree with most of the rest of this: Point 2 part b - access to data by third parties should be a privilege, one which the first party has total control over. It should not be assumed by the presence of the third party on page.Permalink On twitter.com
❤️ 1 Favorite
Mood +1 🙂
-
There are many ways to exercise that control, some are noted, but none suggested. It would be interesting to explore if we accept this world where first to third party identity data is a needed practice.Permalink On twitter.com
Mood +3 🙂
-
The same is restated in the final point. First party control over data transmission on their own site is very very important. 👍Permalink On twitter.com
❤️ 1 Favorite
Mood +4 🙂
-
Ok, last part of this: "A per-first-party identity can only be associated with small amounts of cross-site information" We've already accepted a parallel possibility: no user id data ever needs to be transmitted to third parties. That's one way, here are controls for another.Permalink On twitter.com
❤️ 1 Favorite
Mood 0
-
Ok, so pt 1: Browsers are responsible for a large portion of the balance "between user privacy and web platform usability". Agreed. Then it restates the assumption: there should be a way to join identities. 🤷♂️ Next piece: ...Permalink On twitter.com
Mood +4 🙂
-
The idea is that those identities should be shared but that sharing should be difficult, limited, and "privacy-respecting" and only for "sufficiently useful" cases.Permalink On twitter.com
Mood +1 🙂
-
Which... right... ok, going along with the underlying assumptions here: this is difficult to define, the proposal notes it is a case-by-case level of difficult. Because yeah, of course. There are over 7,000 ad tech companies, they will all want to do this. Difficulty is high.Permalink On twitter.com
♻️ 1 Retweets
❤️ 1 Favorite
Mood 0
-
2nd point: it is ok to share first party data where that data is not particularly personal or identifying. YES, I agree with that all the way. I think it is perfectly fine to note that a user would be interested in a car ad because they are part of a group of many people who are.Permalink On twitter.com
❤️ 1 Favorite
Mood +10 🙂
-
The approach described essentially takes semi-personal information and depersonalizes it by making it representative of a group not an individual. I will have to look deeper into the FLoC API proposal another time but that sounds reasonable. github.com/jkarlin/flocPermalink On twitter.com
Mood 0
-
Next we deal with significantly closer to personally identifiable information which is: if a user clicks on an ad and arrives at cars4days dot com then the site which showed them the ad should get credit for that referral.Permalink On twitter.com
❤️ 1 Favorite
Mood 0
-
I think the linked proposal here needs more work. Apple currently has an alternative one which I am really needing to discuss more on the GitHub there, but I don't think the level of potential personal data transmission is needed in order to measure this. github.com/csharrison/conversion-measurement-apiPermalink On twitter.com
♻️ 2 Retweets
❤️ 1 Favorite
Mood 0
-
This is Apple's proposal for the curious: github.com/WICG/ad-click-attributionPermalink On twitter.com
Mood +1 🙂
-
There's a lot of very technical talk in both proposals about randomness and timing attacks I won't get into, but I think the core question is about how much data an "attribution event" (registering that a user who clicked on an ad also hit another site) contains and transmits.Permalink On twitter.com
❤️ 1 Favorite
Mood -1 🙁
-
There's also a secondary question of who gets to set up the attribution process (publishers or an ad server?) and who gets to receive the event (publishers or an ad server?) that are for another thread, but I think the core here is the amount of data sent matters. Why?...Permalink On twitter.com
Mood +1 🙂
-
The amount of data sent for attribution matters because the more data that can be sent the higher chance someone will use it to create a unique ID for the user that can be reused on multiple sites and then we're back at the beginning again.Permalink On twitter.com
❤️ 2 Favorites
Mood +3 🙂
-
Next point is about sites delegating trust. I think that is important, I previously mentioned privacy pass and the browser level concept is also linked here. github.com/dvorak42/trust-token-apiPermalink On twitter.com
Mood +3 🙂
-
Anyway, I agree that sites need to handle authentication of trusted users and that trust needs to be able to be visible cross-site. Sign-in over multiple sites is a standard of the web now and I think it is a good thing.Permalink On twitter.com
Mood +7 🙂
-
We just have to be careful of how much PII is leaked in this process. (Which is to say: ideally none.)Permalink On twitter.com
Mood +1 🙂
-
Absolutely yes: "It would not be OK for one site to learn the list of all domains visited by a given user"Permalink On twitter.com
❤️ 1 Favorite
Mood +1 🙂
-
Hard to imagine how APIs which allow cross site information could be evaluated to prevent that type of abuse though. That will be very interesting to dive into.Permalink On twitter.com
Mood -2 🙁
-
Ok, I agree with this one. Though I'm not sure what those use cases are. "Any use cases which rely on more than a small amount of cross-site information must not be able to associate that information with any per-first-party identity."Permalink On twitter.com
Mood +1 🙂
-
There's a link to an equally long doc to read next, which presumably dives into this. I'm... going to get to that a little later: github.com/csharrison/conversion-measurement-api/blob/master/AGGREGATE.mdPermalink On twitter.com
Mood 0
-
And there are links to Mozilla's policy: wiki.mozilla.org/Security/Anti_tracking_policy And WebKit's (Apple's) Policy: wiki.mozilla.org/Security/Anti_tracking_policy And yes "Threat models and prevention policies are different parts of the same conversation." But good to read em all yes?Permalink On twitter.com
Mood +3 🙂
-
That's it for now. I think that there are some real challenges to the assumptions in this document worth discussing. And some good stuff too! Also some things worth diving deeper into.Permalink On twitter.com
❤️ 1 Favorite
Mood +7 🙂
-
The top link from Google is open to comment. I'll wait a little while for people to challenge my assumptions or take me to task over errors, but I will likely add a comment in the GitHub issues. Next on my reading list: the details from the blog post itself. But for this thread:Permalink On twitter.com
Mood -1 🙁
-
(One last thing: I hope this made a very difficult subject easier to understand. The future of privacy on the web is important to us all, and I'd like it if more non-engineers could understand what's happening with it.)Permalink On twitter.com
❤️ 8 Favorites
Mood +5 🙂
-
I agree, the way I framed it missed that graf 3 was noting the state of things today as the problem (not the future solution), though I think we may disagree about what elements of the problem need to be corrected, I want to add the author's clarification: Log3overLog2/1164590816901378048Permalink On twitter.com
❤️ 1 Favorite
Mood -5 🙁
-
This is a good point: I was unclear on this, but yes: keep in mind that the total of this is purely about web apps, though the spec being discussed is potentially inspired by the issues of app authentication. Log3overLog2/1164594232088301568Permalink On twitter.com
❤️ 1 Favorite
Mood +5 🙂
-
(To be clear web sites not phone apps)^Permalink On twitter.com
Mood +1 🙂
-
A correction to my interpretation of third party sets here, It looks like they may not be as pervasively defined as I had thought in my first reading: Log3overLog2/1164623649338511360Permalink On twitter.com
Mood +2 🙂
-
Permalink
On twitter.com
Mood 0
-
(Note: I'm posting conversations as I resolve them with the author of the piece, the author is responding to each tweet with issues with my assumptions, interpretation, etc... which I very much appreciate and encourage you to read)Permalink On twitter.com
❤️ 2 Favorites
Mood +6 🙂